LangChain-ChatGLM 基于本地知识库的问答 ChatGLM-6B简介 它是一个开源的,支持中英双语的对话语言模型,基于General Language Model(GLM)架构,具有62亿参数
ChatGLM-6B应用 大语言模型通常基于通识知识进行训练,因此在面向如下场景时,常常需要借助模型微调或提示词工程提升语言模型应用效果
微调和提示词工程
名词
是什么
适用场景
微调
针对预先训练的语言模型在特定任务的少量数据集上对其进行进一步训练
当任务或域定义明确,并有足够的标记数据可供训练时,通常使用微调过程
提示词工程
涉及设计自然语言提示或指令,可以指导语言模型执行特定任务。
最适合需要高精度和明确输出的任务。提示工程可用于制作引发所需输出的查询
LangChain介绍(提示词工程框架) LangChain简介 Langchain是一个用于开发由语言模型驱动的应用程序的框架
调用语言模型
将不同数据源接入到语言模型的交互中
允许语言模型与运行环境交互
LangChain中提供的模块
Modules:支持的模型类型和集成
Prompt:提示词管理、优化和序列化。
Memory:内存是指在链/代理调用之间持续存在的状态
Indexes:当语言模型与特定于应用程序的数据相结合时,会变得更加强大-此模块包含用于加载、查询和更新外部数据的接口和集成。
Chain:链是结构化的调用序列(对LLM或其他实用程序)
Agents:代理是一个链,其中LLM在给定高级指令和一组工具的情况下,反复决定操作,执行操作并观察结果,直到高级指令完成。
Calbacks:回调允许您记录和流式传输任何链的中间步骤,从而轻松观察、调试和评估应用程序的内部。
LangChain应用场景
文档问答:在特定文档上回答问题,仅利用这些文档中的信息来构建答案
个人助理:个人助理需要采取行动,记住互动,并了解您的数据。
查询表格数据:使用语言模型查询库表类型结构化
与API交互:使语言模型与API交互非常强大。它允许他们访问最新信息,并允许他们采取行动
信息提取:从文本中提取结构化信息
文档总结:压缩较长文档,一种数据增强生成
基于单一文档问答的实现原理
加载本地文档:读取本地文档加载为文本
文本拆分:将文本按照字符,长度或语义进行拆分
根据提问匹配文本:根据用户提问对文本进行字符匹配或语义检索(需要向量化)
构建Prompt:将匹配文本,用户提问,加入Prompt模板
LLM生成回答:将Prompt发送给LLM获得基于文档内容的回答
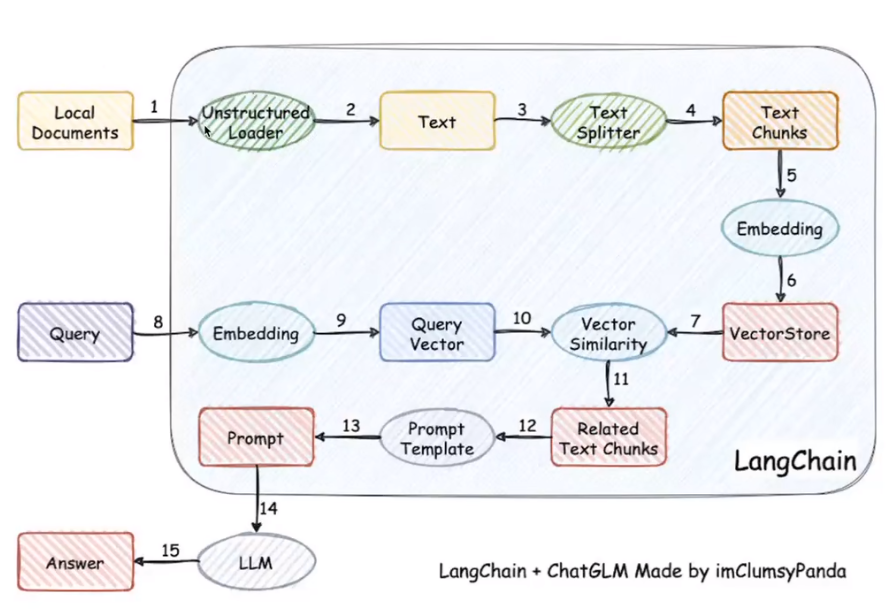
基于本地知识库的问答实现原理
1,2 文本加载
3,4 文本拆分
5,6文本向量化形成Vectorstore向量数据库
8 将查询的文本向量化
9,10 到向量数据库里面进行已有文段的匹配
11 形成相关文段
12 转化为Prompt Template(引导LLM模型生成特定类型响应的一种格式输入方式)的形式
13 填充到Prompt当中
14 发送至LLM(大语言模型)
15 LLM回复
基于本地知识库的问答的代码实现(简易版) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 from transformers import AutoTokenizer,AutoModeltokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b" ,trust_remote_code=True ) model = AutoModelfrom_pretrained("THUDM/chatglm-6b" ,trust_remote_code=True ).half().cuda()chatglm = model.eval () from langchain.document_loaders import UnstructuredFileLoaderfrom langchain.text_splitter import CharacterTextSplitterfrom langchain.embeddings.openai import :OpehAIEmbeddingsfrom langchain.vectorstores import FAISSfilepath = "test.txt" Loader = UnstructuredFileLoader(filepath) docs = Loader.load() text_splitter = CharacterTextSplitter(chunk_size = 500 ,chunk_overlap = 200 ) docs = text_splitter.split_text(docs) embeddings = OpenAIEmbeddings() vector_store = FAISS.from_documents(docs,embeddings) query = "LangChain 能够接入哪些数据类型?" docs = vector_store.similarity_search(query) context = [doc.page_content for doc in docs] prompt = f"已知信息:\n{context} \n根据已知信息回答问题:\n{query} " chatglm.chat(tokenizer,prompt,history=[])
LangChain-ChatGLM项目简介 Langchain-ChatGLM是一个基于ChatGLM等大语言模型的本地知识库问答实现
项目特点:
依托ChatGLM等开源模型实现,可离线部署
基于langchain实现,可快速实现接入多种数据源
在分句、文档读取等方面,针对中文使用场景优化
支持pdf、txt、md、docx等文件类型接入,具备命令行demo、webui和vue前端
models:LLM的接口类与实现类,针对开源模型提供流式输出支持
loader:文档加载器的实现类
textsplitter:文本切分的实现类
chains:工作链路实现,如chains/local_doc_qa实现了基于本地文档的问答实现
content:用于存储上传的原始文件
vector_store:用于存储向量库文件,即本地知识库本体
configs:配置文件存储
项目部署 ChatGLM环境部署 项目下载 1 git clone https://github.com/THUDM/ChatGLM-6B.git
环境安装 用conda创建python3.10环境
1 conda create --name ChatGLM-6B python=3.10
启动该环境
1 conda activate ChatGLM-6B
安装相关依赖
1 pip install -r requirements.txt
ChatGLM3-6B模型下载 已经下载git LFS 的情况下
1 2 3 4 5 // 有代理就用huggingface git clone https://huggingface.co/THUDM/chatglm-6b // 无代理用modelscope git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
本地代码调用模型(测试) 1 2 3 4 5 6 from transformers import AutoTokenizer, AutoModeltokenizer = AutoTokenizer.from_pretrained("E:\ChatGLM3-6b-model" , trust_remote_code=True ) model = AutoModel.from_pretrained("E:\ChatGLM3-6b-model" , trust_remote_code=True ).half().cuda() model = model.eval () response, history = model.chat(tokenizer, "你好" , history=[]) print (response)
改成相对应的模型文件夹绝对路径 1 2 tips:在编译器里面运行时一定要选择conda创建的那个python解释器,或者直接命令行运行也行,如下
conda activate <环境名称>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31  如果出现报错,扔给gpt,结合gpt的分析去解决,不要无脑跟着输入命令 #### ChatGLM项目调用模型 ##### 本地API开放 只需要将所有```THUDM/chatglm-6b``` 替换为相对应的模型文件夹绝对路径 然后用 ```python api.py ``` 开放API即可  ##### 本地API调用测试 直接request发post包即可 示例代码: ```py import requests def Chat(prompt,history): url = "http://127.0.0.1:8000" json = {"prompt": prompt, "history": history} headers = {"Content-Type": "application/json;charset=UTF-8"} response = requests.post(url=url,json=json,headers=headers) return response.json()['response'], response.json()['history'] history = [] while True: response, history = Chat(input("问题:"),history) print("回答:",response)
测试结果:
langchain加载ChatGLM langchain依赖安装 在你的python项目下面
加载ChatGLM模型 创建一个langChainLoadChatGLM.py文件用来加载ChatGLM
1 2 3 4 5 6 7 8 9 from langchain.llms import ChatGLMendpoint_url = "http://127.0.0.1:8000" llm = ChatGLM( endpoint_url = endpoint_url, max_token = 80000 , top_p = 0.9 )
后续完善文档分割和向量化,写prompt模板即可
Fay部署+联动UE数组人 Fay部署 Fay环境安装 使用conda创建虚拟环境(推荐)或者直接下载python3.10
1 2 conda create --name Fay python=3.10 conda activate Fay
Fay项目拉取,依赖下载 项目拉取:
1 git clone https://github.com/TheRamU/Fay.git
cd到Fay项目的主目录下,安装依赖
1 pip install -r requirements.txt
配置Fay的key 配置Fay项目下的system.conf文件,把需要的Apikey配置好
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 [key] #funasr / ali ASR_mode = ali #ASR二选一(需要运行fay/test/funasr服务)集成达摩院asr项目、感谢中科大脑算法工程师张聪聪提供集成代码 local_asr_ip=127.0.0.1 local_asr_port=10197 # ASR二选一(第1次运行建议用这个,免费3个月), 阿里云 实时语音识别 服务密钥(必须)https://ai.aliyun.com/nls/trans ali_nls_key_id= ali_nls_key_secret= ali_nls_app_key= # 微软 文字转语音 服务密钥(非必须,使用可产生不同情绪的音频)https://azure.microsoft.com/zh-cn/services/cognitive-services/text-to-speech/ ms_tts_key= ms_tts_region= # 讯飞 情绪分析 服务密钥 https://www.xfyun.cn/service/emotion-analysis/ xf_ltp_app_id= xf_ltp_api_key= #NLP多选一:xfaiui、yuan、chatgpt、rasa(需启动chatglm及rasa,https://m.bilibili.com/video/BV1D14y1f7pr)、VisualGLM chat_module=xfaiui # 讯飞 自然语言处理 服务密钥(NLP3选1) https://aiui.xfyun.cn/solution/webapi/ xf_aiui_app_id= xf_aiui_api_key= #浪.潮源大模型 服务密钥(NLP3选1) https://air.inspur.com/ yuan_1_0_account= yuan_1_0_phone= #gpt 服务密钥(NLP3选1) https://openai.com/ chatgpt_api_key= #ngrok内网穿透id,远程设备可以通过互联网连接Fay(非必须)http://ngrok.cc ngrok_cc_id= #revChatGPT对接(非必须,https://chat.openai.com登录后访问https://chat.openai.com/api/auth/session获取) gpt_access_token= gpt_conversation_id=
启动 conda的虚拟环境,下面然后启动main.py即可python main.py
UE数字人下载 下载开源数字人项目 https://github.com/xszyou/fay-ue5
下载好想要的项目即可,注意需要的ue版本
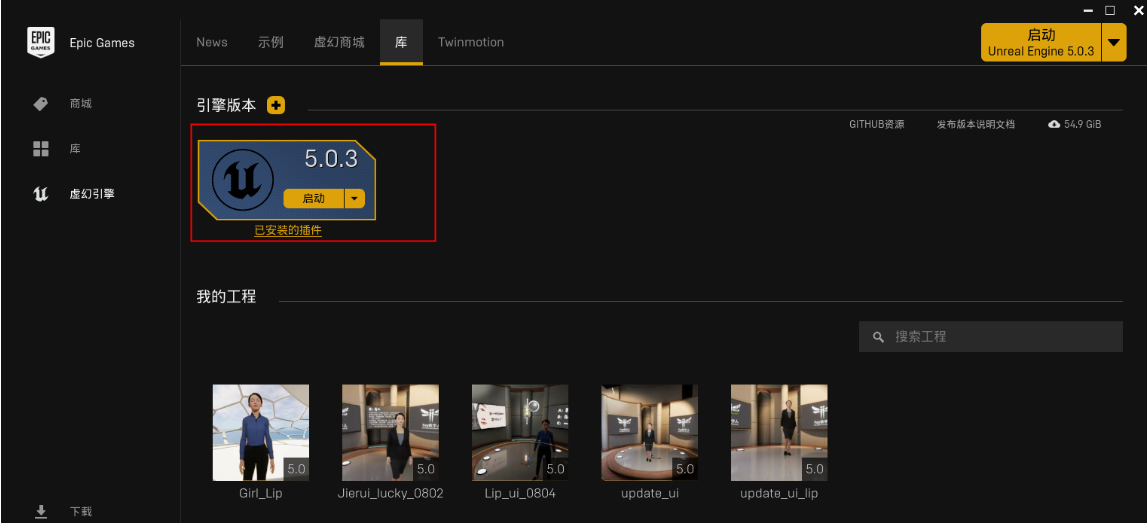
下载Epic 官网: https://www.unrealengine.com/en-US/unreal-engine-5
下载虚拟引擎UE以及需要的插件 本文下载的是ue5.0.3,根据你下载的数字人项目去下载对应版本的引擎
然后直接打开数字人项目文件夹下面的.uproject文件,运行即可