
爬虫
request模块
模块导入
1 | import requests |
使用request模块发送get,post请求
- response = requests.get(url,headers=headers,params,timeout)
- response = requests.post(url,data={请求体的字典})
参数说明如下 - url:要抓取的 url 地址。
- headers:用于包装请求头信息,以字典形式,一般包装useragent。
- params:请求时携带的查询字符串参数。
- timeout:超时时间,超过时间会抛出异常,例如 timeout = 3 设置超时时间为3秒
发送请求后服务器返回一个 HttpResponse 响应对象
将其打印出来
1 | import requests |
得到
1 | <Response [200]> |
该HttpResponse 响应对象具有以下常用属性:
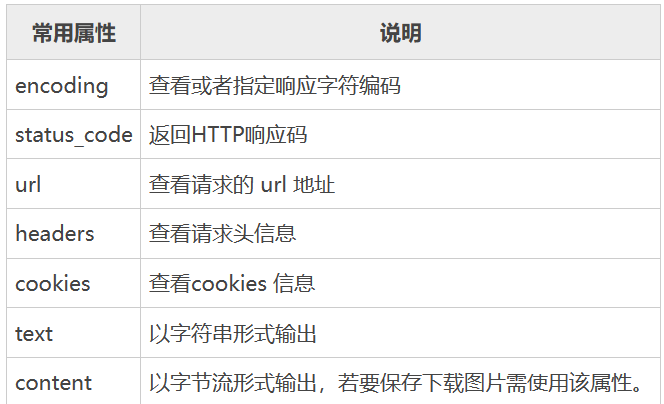
response 的几种方法
- print(response.encoding) # 打印编码格式
- response.encoding=”utf-8” # 更改为utf-8编码(一般网页为utf-8编码格式)
- print(response.text) # 以字符串形式打印网页源码
该方式往往会出现乱码,往往配合response.encoding使用 - print(response.content) # 以二进制字节流形式打印网页源码
以二进制字节流形式打印中文会不显示,一般用**response.content.decode()**将响应的二进制字节流形式转化为str类型,括号内可以指定编码格式,如果不填,默认为utf-8,有时候中文无法显示可以用”gbk”的编码格式去解码 - print(response.status_code) # 打印状态码
- print(response.url) # 打印响应的url地址
- print(response.request.url) # 打印发送请求的url地址
一般响应的url地址和发送请求的url地址是一样的,除非发生重定向,使得响应的url和发生时的url不一样 - print(response.headers) # 打印响应头信息
- print(response.request.headers) # 打印请求头信息
- print(response.cookies) # 打印cookie信息
处理需要携带cookie的请求
- 直接携带cookie请求url地址
- 将cookie放在headers中:
直接去浏览器中复制cookie字符串,加在headers中 - 将cookie字符串转为字典形式然后再传给cookies参数:
requests.get(url,cookies=cookie_dict)
其中,可以用字典推导式,快速将cookie以字符串形式转化为字典形式,代码如下:运行结果为1
2
3cookie = "phid=6666; sid=999"
cookie_dict = {i.split("=")[0]:i.split("=")[-1] for i in cookie.split(";")}
print(cookie_dict)1
{'phid': '6666', ' sid': '999'}
- 将cookie放在headers中:
- 先发送post请求,获取cookie,再带上cookie去请求登录后的页面
- 实例化session(session具有的方法和requests一样)
session = requests.session() - 用session去发送一个post请求得到保存在本地的cookie(cookie会保存在session中)
session.post(url,data,headers) - 再使用session去请求登录后的页面
response = session.get(url,headers)
- 实例化session(session具有的方法和requests一样)
retrying模块
模块导入
1 | from retrying import retry |
使用方法:
在请求响应的函数前面加上@retry方法
如:
1 | @retry(stop_max_attempt_number=3) #让被装饰的函数反复执行三次,三次全部报错才会报错 |
使用fake-useragent模块来伪造User-Agent
短时间内总使用一个 UA 高频率访问的网站,可能会引起网站的警觉,从而封杀掉 IP,所以我们构造多个UA来绕过
1 | from fake_useragent import UserAgent |
运行结果为:
1 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 OPR/99.0.0.0 |
爬虫程序中的具体使用
1 | from fake_useragent import UserAgent |
json 模块
当响应包为json格式数据就要用到python中json模块去解析
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,常用于前后端之间的数据传输和存储,遵循欧洲计算机协会制定的 JavaScript 规范(简称 ECMAScript)。JSON 易于人阅读和编写,同时也易于机器解析和生成,能够有效的提升网信息的传输效率,因此它常被作为网络、程序之间传递信息的标准语言,比如客户端与服务器之间信息交互就是以 JSON 格式传递的。
简单地说,JSON 可以将 JavaScript 对象表示的一组数据转换为字符串格式,以便于在网络、程序间传输这个字符串。并且在需要的时候,您还可以将它转换为编程语言所支持的数据格式。本节主要介绍如何实现 JSON 数据与 Python 数据类型间的相互转换。
json类型数据的格式
JSON数据由键值对组成,使用大括号({})表示对象,使用方括号([])表示数组。每个键值对由一个键和一个对应的值组成,键和值之间使用冒号(:)分隔,多个键值对之间使用逗号(,)分隔。值可以是字符串、数字、布尔值、对象、数组或null。
以下是JSON格式的示例:
1 | { |
操作示例:
1 | import json |
json模块的方法总结
| 方法 | 作用 |
|---|---|
| json.dumps() | 将 Python 对象转换成 JSON 字符串。 |
| json.loads() | 将 JSON 字符串转换成 Python 对象。 |
| json.dump() | 将 Python 中的对象转化成 JSON 字符串储存到文件中。 |
| json.load() | 将文件中的 JSON 字符串转化成 Python 对象提取出来。 |
综上所述 json.load() 与 json.dump() 操作的是文件流对象,实现了 json 文件的读写操作,而 json.loads() 与 json.dumps() 操作的是 Python 对象或者 JOSN 字符串。
xpath 语言和lxml 模块
XPath(全称:XML Path Language)即 XML 路径语言,它是一门在 XML 文档中查找信息的语言,最初被用来搜寻 XML 文档,同时它也适用于搜索 HTML 文档。因此,在爬虫过程中可以使用 XPath 来提取相应的数据。
xpath语法
- xpath helper插件:帮助我们从elements中定位数据
- 选择节点(标签):
/html/head/meta:能够选中htm下的head下的所有的meta标签 - //:能够从任意节点开始选择
- //1i:当前页面上的所有的li标签
- /html/head//link:head下的所有的link标签
- . : 表示当前节点
- .. : 表示当前节点的父节点
- @符号的用途:
- 选择具体某个元素://div[@class=’feed’]/ul/li
- 选择class=feed的div下的ul下的li
- a/@href:选择a的href的值
- 获取文本:
- /a/text():获取a下的文本
- /a//text():获取a下的所有的文本
- 选择节点(标签):
lxml 模块
- 导入模块: import lxml
- lxml模块的使用:
lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档,使用该模块来解析html/xml文档的流程如下
- 导入
1
from lxml import etree
- 创建解析对象
调用 etree 模块的 HTML() 方法来创建 HTML 解析对象。如下所示:HTML() 方法能够将 HTML 标签字符串解析为 HTML 文件,该方法可以自动修正 HTML 文本。示例如下:1
parse_html = etree.HTML(html)
输出结果如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15from lxml import etree
html_str = '''
<div>
<ul>
<li class="item1"><a href="www.python.com">Python</a></li>
<li class="item2"><a href="www.java.com">Java</a></li>
<li class="site2"><a href="www.baidu.com">百度</a>
<li class="site3"><a href="www.jd.com">京东</a></li>
</ul>
</div>
'''
html = etree.HTML(html_str)
# tostring()将标签元素转换为字符串输出,注意:result为字节类型
result = etree.tostring(html)
print(result.decode('utf-8'))1
2
3
4
5
6
7
8<html><body><div>
<ul>
<li class="item1"><a href="www.python.com">Python</a></li>
<li class="item2"><a href="www.java.com">Java</a></li>
<li class="site2"><a href="www.baidu.com">百度</a></li>
<li class="site3"><a href="www.jd.com">京东</a></li>
</ul>
</div></body></html> - 调用xpath表达式
最后使用第二步创建的解析对象调用 xpath() 方法,完成数据的提取,如下所示:输出结果为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16from lxml import etree
html_str = '''
<div>
<ul>
<li class="item1"><a href="www.python.com">Python</a></li>
<li class="item2"><a href="www.java.com">Java</a></li>
<li class="site2"><a href="www.baidu.com">百度</a>
<li class="site3"><a href="www.jd.com">京东</a></li>
</ul>
</div>
'''
html = etree.HTML(html_str)
# 提取文本数据,以列表形式输出
# 注:xpath只能根据当前url对应的响应的来写(一般情况下element和响应的html不一样)
result = html.xpath('//li/a/@href')
print(result)1
['www.python.com', 'www.java.com', 'www.baidu.com', 'www.jd.com']
对编写爬虫程序的一些个人见解
- 一般编写爬虫程序分为四步:
- 第一步:初始化参数
url的构造,headers,cookies等的伪造 - 第二步:请求
用requests方法去请求url,获得网页的响应 - 第三步:解析
对网页的响应进行解析,将其中需要爬取的数据提取出来(re,xpath,bs4) - 第四步:保存
将提取出来的数据进行保存,用数据库或者文件的操作来实现
- 第一步:初始化参数
关于反爬和绕过
爬虫实战中一般有许多网站有反爬虫的一些策略,需要更多的深度学习来进行绕过
- 网站反爬虫策略主要有以下几种:
基于IP的反爬虫:通过人为或部分策略来识别出爬虫的IP并进行屏蔽、阻止、封禁等操作。
基于爬行的反爬虫:在爬虫的爬行中设置爬行障碍,让其陷入死循环;或者用一些无意义的URL来填充其爬行队列,从而阻止其对正常URL进行后续的漏洞审计。
封User-Agent:User-Agent是请求头域之一,服务器从User-Agent对应的值中是被客户端的使用信息。User-Agent的角色就是客户端的身份标识。很多的爬虫请求头就是默认的一些很明显的爬虫头python-requests/2.18.4,诸如此类,当发现携带有这类headers的数据包,直接拒绝访问,返回403错误。
封Cookie:服务器通过校验请求头中的Cookie值来区分正常用户和爬虫程序。
JavaScript渲染:由JavaScript改变HTML DOM导致页面内容发生变化的现象称为动态渲染。由于编程语言没有像浏览器一样内置JavaScript解释器和渲染引擎,所以动态渲染是天然的反爬虫手段。
验证码验证:当某一用户访问次数过多后,就自动让请求跳转到一个验证码页面,只有在输入正确的验证码之后才能继续访问网站。
Ajax异步传输:访问网页的时候服务器将网页框架返回给客户端,在与客户端交互的过程中通过异步ajax技术传输数据包到客户端,呈现在网页上,爬虫直接抓取的话信息为空。
图片伪装:将带有文字的图片与正常文字混合在一起,以达到“鱼目混珠”的效果。
CSS偏移:利用CSS样式将乱序的文字排版为人类正常阅读顺序1。
SVG映射:SVG是用于描述二维矢量图形的一种图形格式。它基于XML描述图形,对图形进行放大或缩小操作都不会影响图形质量。由于SVG中的图形代表的也是一个个文字,所以在使用时必须在后端或前端将真实的文字与对应的SVG图形进行映射和替换
2. 一些常见的绕过思路
cookie中一些参数的绕过(如:uuid)
用session方法